[NLP] FinRED와 Relation Extraction (1)
Intro
Financial Domain에 맞는 Relation Extraction Downstream Task로 FinRED를 사용하기로 했다.
초반에 Relation Classification과 Relation Extraction의 개념이 같다고 생각하여 Relation Classification Task만을 생각하고 구현하다가 DataLoader 쪽에서 에러가 나면서 다시 처음부터 생각해보게 되었고, 결과 지금과 다른 접근을 해야한다고 결론을 내게 되었다.
이에 FinRED 논문을 다시 차근차근 읽어보게 되었다.
Relation Classification
어제까지만 해도 Relation Extraction이 Relation Classification과 완전 같다고 생각하고 코드를 짰다.
찾아봤을 때, BERT(S) for Relation Extraction in NLP에서 Matching the Blanks: Distributional Similarity for Relation Learning 논문을 References에 올려두었고 Relation Classification을 논문의 그림 위에 Linear 레이어를 쌓아 Classification을 하는 것처럼 모델을 구현하려고 노력했다.
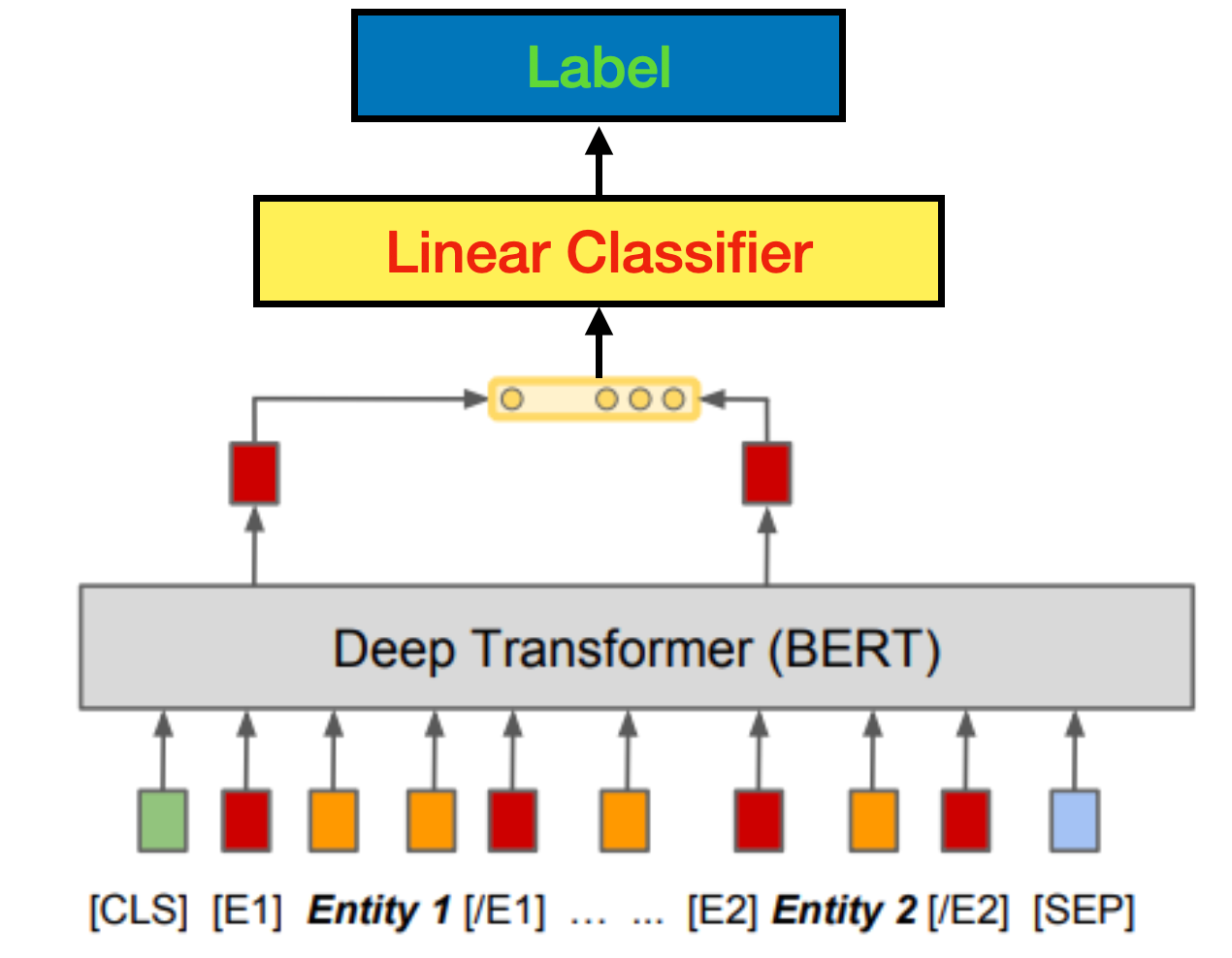
그림처럼 데이터에 (entity1, entity2, relation)이라는 triplet이 있을 때 triplet에서 entity1과 entity2를 찾아 각각 special token [E1], [/E1], [E2], [/E2]를 넣어주려고 했으나 다음과 같은 문제점이 발생했다.
Problems
- Entity Token 삽입 시 문제
- Entity1, Entity2에 포함되는 문자가 있는 경우(Apple, Apple Inc)
- Entity 뒤에 +가 있는 경우(Apple TV+ ← 원문 : Apple TV set-top box)
- Entity1과 Entity2가 완전 동일한데 Relation이 여러 개인 경우
- Apple TV+ ; Apple Inc ; operator
- Apple TV+ ; Apple Inc ; owned_by
- Apple TV+ ; Apple Inc ; parent_organization
- 그 외의 경우
- which is the main strength of HDFC Bank, the training and the HDFC Bank team. (hdfc, HDFC Bank)
이러한 문제점들로 FinRED 데이터셋 논문부터 다시 차근차근 읽어보기로 했다.
FinRED
1. Data Sources
- Webhose Financial News : 47851 financial news
- Earning Call Transcripts : 4713 ECTs(2019/6~2019/9) from seekingalpha
- Knowledge Base : Wikidata KB의 subset - 29개의 financial relation으로 필터링
2. Experiments
- 외부 NER 모듈 사용 안 함
- 3개의 joint entity and relation extraction model(SPN, TPLinker, CasRel)로 실험
- Exact entity matching 기준에 따라 triplet 추출에 대한 metric 구함
3. Mini Conclusion
외부 NER 모듈을 사용하지 않는다는 점, joint entity and relation extraction model이라는 새로운 모델로 평가지표를 만들었기 때문에 우리 모델도 joint방식을 사용해야 한다 생각했고 이에 관련 논문을 찾아보았다.
Relation Extraction
joint entity and relation extraction model을 검색하여 Deep Neural Approaches to Relation Triplets Extraction: A Comprehensive Survey 논문을 읽어보게 되었다.
1. Task Description
이 논문에서 정의하는 Relation Extraction은 다음과 같다.
relation R과 문장에서 relation triplet들의 set을 추출하는 것
또한 두 가지의 sub-task로 이루어져 있는데
- Entity Recognition : 모든 entity 후보를 문장에서 찾고
- Relation Classification : 추출한 entity 후보 간 가능한 모든 relation을 추출한다.
여기서 문장은 세 개의 class로 분류된다.
- No Entity Overlap(NEO) : 1개 이상의 triplet 가지지만 어떤 entity도 공유하지 않는다.
- Entity Pair Overlap(EPO) : 1개보다 많은 triplet 가지고 최소 2개 triplet은 entity가 같거나 그 순서가 반대로 되어 있다.
- Single Entity Overlap(SEO) : 1개보다 많은 triplet 가지고 최소 2개의 triplet에서 단 하나의 entity를 공유한다.

2. Relation Extraction Models
본 논문에서 여러 가지 방법을 제시했는데 기본적인 Pipeline Approach와 FinRED에 나온 Joint Extraction Approach 두 가지만 적어둔다.
1. Pipeline Approach
entity가 이미 식별되었다고 가정하고 model이 relation을 분류한다.
즉, spaCy나 BERT 등의 모델의 NER로 entity를 추출하고 나서 model이 추출한 entity 쌍으로 Relation Classification을 학습하는 것이다.
위에서 언급한 문제점들 중 하나인 Entity가 동일한데 Relation이 다른 경우를 noisy data라고 하는데 이 noisy data 때문에 F1은 평가하기 부적합하기 때문에 Precision, Recall을 사용하여 평가한다고 한다.
2. Joint Extraction Approach
문장에서 추출된 정답 triplet의 수에 근거하여 평가한다고 한다. 중복 triplet은 제거한다.
Joint Extraction Approach는 Entity Recognition과 Relation Identification의 파라미터를 공유해서 최적화도 함께한다고 한다.
같은 네트워크에서 NER과 Relation Classification을 같이 하지만 NER을 먼저하고 Relation Classification을 나중에 한다고 한다.
평가할 때 Partial(P)와 Exact(E) 두 가지로 하여 평가할 수 있는데 Partial은 Entity Token의 마지막이 일치하면 정답으로 하는 것이고 Exact는 Entity Token의 전체가 일치해야 정답으로 하는 것이다.
Conclusion
먼저 Relation Classification만 하던 기존 모델에서 Joint Model 방식으로 바꾸어 진행하려고 한다.
Deep Neural Approaches to Relation Triplets Extraction: A Comprehensive Survey 논문에서 평가한 모델들 중에 FinRED: A Dataset for Relation Extraction in Financial Domain에서 사용한 세 모델(SPN, TPLinker, CasRel) BERT 버전이 있어 해당 모델들의 논문을 참고하여 Joint Entity and Relation Extraction Model을 만들어보려고 한다.
또 Relation Classification을 구현을 직접 해야 한다면 DocRED 논문에 나오는 방식으로 진행해보려고 한다.
위에 적었던 나머지 문제점들에 대해서도 해결할 수 있도록 할 것 같으며 RoBERTa의 최대 토큰 길이가 512인 것이 FinRED 최대 토큰 길이 2000이 넘는 것을 해결 가능한지에 대해서도 알아볼 예정이다.